Reinforcement Learning: Develop AI-Based Controllers For A Heat Recovery Steam Generator System


This blog post details the innovative use of reinforcement learning (RL) to develop AI-based controllers for a heat recovery steam generator system. By combining Modelon Impact and minds.ai’s DeepSim platform, engineers are able to take advantage of the latest developments in AI without having to upend current workflows, learn new technologies, or design new models.
Reinforcement Learning Using Modelon Impact and DeepSim Capabilities
What is reinforcement learning? Reinforcement learning (RL) is a branch of machine learning where the goal of the agent (an intelligent neural network, in this case, a system controller) is to maximize a reward function by making sequential decisions or actions that affect the current environment of the agent. The agent’s environment (or mechanical system in this case) can be modeled in a simulator, a hardware-in-the-loop system, or by a previously recorded dataset.
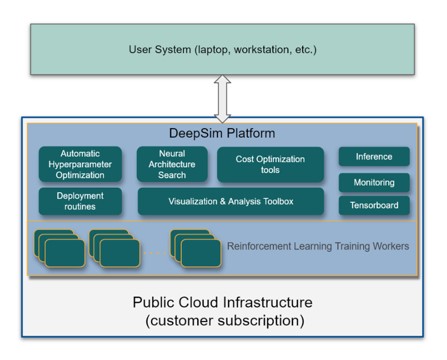
A robust and detailed simulation of the system to be controlled is critically important when training an intelligent agent with the minds.ai DeepSim platform. Modelon and minds.ai have partnered to answer this critical dependency by integrating DeepSim with the solvers that come with Modelon Impact to enable any of our joint customers to easily put RL to work solving their most pressing control challenges.
Modelon Impact is a cloud-native system simulation software platform featuring a unique, easy-to-use web-based interface; allowing users to move through layers of sub-systems – building and analyzing models, components, and code. Modelon’s comprehensive, proven, and multi-physics libraries are built-in and easily accessible. The benefits of using physics-based models for this development workflow means that everything can be developed and tested in the virtual environment. Some advantages include:
- Scalability – easy to add more compute power to speed up the development process
- Safety – no actual hardware is required during the exploration phases
- Ease to validate a range of different model/hardware designs
- Ability to detect correlation with the rest of the system (with a digital twin, bottlenecks throughout the system can easily be detected)
- Affordability – by performing the full design analysis in software, there is no need to construct and build physical systems
minds.ai is an artificial intelligence product company with global dedicated support offerings to ensure customer success with automating controller and design workflows. minds.ai’s easy-to-use DeepSim platform is a deep reinforcement learning platform designed to abstract the RL algorithm’s intricacies, allowing a domain expert to incorporate their expertise into DeepSim through the designing of the reward function. By parallelizing the RL training over multiple processes, DeepSim speeds up the development and time-to-market while utilizing the allocated resources optimally.
Heat Recovery Steam Generators
Heat Recovery Steam Generators (HRSGs) generate electricity by using heat from the flue gases escaping thermal power plants to recover most of the lost heat energy while cooling down the hot gases. The model shown in Figure 2 below has been developed using Modelon Impact.
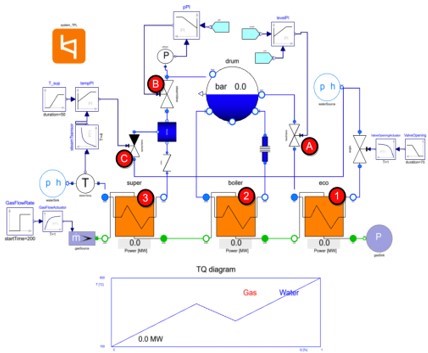
The HRSG has three heat-exchangers carrying water in different phases, represented by the orange boxes at the bottom of Figure 2 (the red circles with numbers match the numbers below):
- Water enters through the economizer (the heat exchanger on the bottom-right). Its temperature rises by coming into contact with the escaping flue gases, which have already lost most of their heat energy in the other heat exchangers.
- The heated water then enters the boiler, where some of it is converted into gas by getting heated by relatively hotter flue gases. Thus, in the boiler, the water exists in 2 phases – liquid and gas.
- Finally, the steam is allowed to enter the superheater, where it gets further heated by the flue gases. The gasses enter the HRSG system through the same superheater and hence are at their highest temperature.
Water and steam entry is regulated by three valves actuated using PI controllers, including the:
- Feed Valve: This regulates the entry of heated water from the economizer into the boiler drum, where liquid water co-exists with the steam. The controller maintains a prescribed level of liquid water in the drum (circle A).
- Steam Valve: This regulates the entry of steam from the boiler drum into the superheater. The PI controller maintains a prescribed steam pressure in the drum (circle B).
- Spray Valve: This regulates the opening of a water spray attemperator which cools the superheated steam. The PI controller maintains the prescribed temperature of the escaping steam (circle C).
Designing AI-Based Controllers for HRSGs Using Reinforcement Learning
This project aimed to replace the three PI controllers used for actuating the feed, steam, and spray valves, with reinforcement learning (RL) agents trained using DeepSim. The objective is to develop controllers that improve the performance of the standard PI controllers, to ensure the three sensor readings – steam pressure, steam temperature, and water level in the drum are as close as possible to the prescribed values set by the plant designer.
To have DeepSim interact with the simulator model, the PI controllers were replaced with external inputs allowing DeepSim to dictate the actions to be taken. This was a seamless step to implement in Modelon Impact. After this step, the model was exported to an FMU model, which was then loaded into the DeepSim platform. This workflow is universal and can be applied to any models designed and supported by Modelon Impact.
The problem statement for the HRSG controllers was set up such that the RL agent would give three commands to the model which were sent during each time step of the execution. Since the agent would explore different values for these commands, the action space was constrained to prevent the system from reaching an irrecoverable state. The three commands that were empirically determined to perform well in the following ranges are:
- steamValveCommand: 0.033 to 0.67
- sprayValveCommand: 0.004 to 0.083
- feedValveCommand: 0.033 to 0.67
At the same time, the agent would monitor the following sensor readings: steamPressure, steamTemperature, and drumLevel. The most important part of any RL problem statement is the definition of the reward function, as this function determines what the agent is ultimately going to learn to optimize.
RL controllers can be compared to conventional Model Predictive Control (MPC) controllers. In MPC the control action is obtained by solving a finite horizon open-loop optimal control problem at each sampling instant. The reward function in RL is similar to the objective function used by the MPC and like an MPC controller, the RL controllers are open-loop taking feedback only in the form of the next environment state. However, the two methods are not the same. MPC requires an online computation of the control variable, while RL only requires this during the training phase as during deployment a simple matrix multiplication is sufficient. Another difference is that the RL solution uses the system model to explore the parameter space and maximize the reward whereas the MPC method uses the system model and constraints to optimize the objective function. This means that increasing model complexity does not make the task tougher for RL while it does for an MPC solution.
HRSG System Results From Actions of AI-Based Controllers
In this example, the proximal policy optimization algorithm was used as it works well for sophisticated simulation platforms like Modelon Impact. For tuning the hyperparameters of the RL algorithm, multiple DeepSim experiments were run in parallel over 32 CPU cores where each run used slightly different parameters.
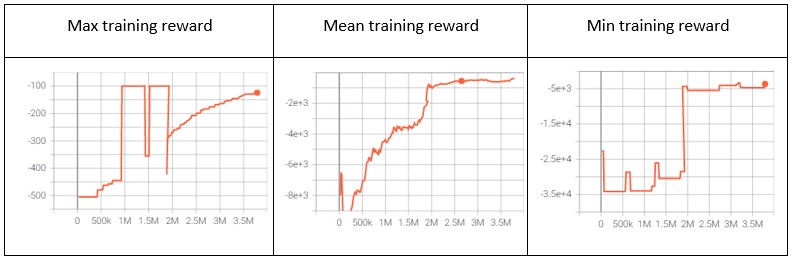
Figure 3 shows that the minimum and mean rewards have reached a plateau (higher is better), indicating that the agent is satisfied with all the training examples (scenarios) that it has seen. The x-axis shows that it took the agent a little over 3.5 million steps to be trained. This translates to 3.5M simulator interactions to get information about the updated state of the model.
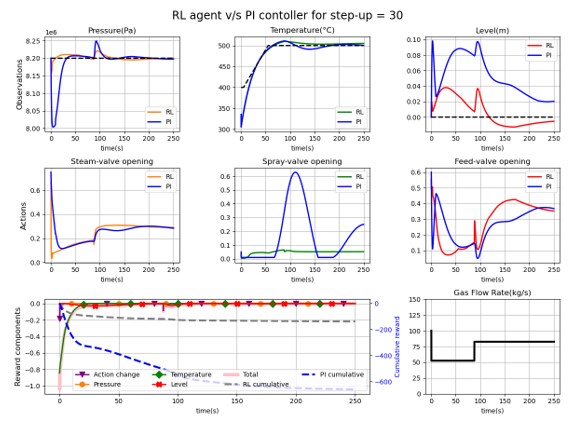
To validate and compare the RL agent controller performance vs. the traditional PI controller, a set of evaluation scenarios were used to evaluate how the HRSG system responded to the actions of these controllers. Figure 4 compares the two types of controllers using one of the evaluation scenarios. For reference, the agent has been compared against the corresponding PI controller. In these plots, the first row shows observations along with their set values. The second row shows the actions taken. Finally, the third row shows the reward components of the agent and the gas flow rate for the evaluation episode, including the randomly induced change in gas flow rate to test the adaptability of the controllers. Figure 4 also illustrates that the RL agent gets closer to the set values, and more importantly, reacts faster than the traditional PI controller. This demonstrates that the RL controllers adapt to changing situations more quickly, which is important for these highly dynamic systems.
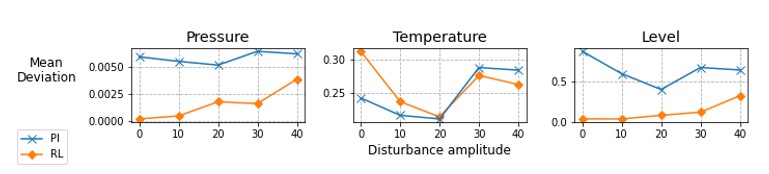
The final evaluation of the mean deviations from the set values for the RL agent and PI controllers reveals an overall better performance of the RL agent, shown below in Figure 5. The deviations increase with the increasing amplitude of disturbance in the input but remain below the same for the PI controller.
Conclusion
By combining Modelon Impact and the DeepSim platform, users can take advantage of the latest developments in AI without having to upend current workflows, learn new technologies, and design new models. Using RL to generate controllers, swiftly iterate through various innovative designs and make a controller more robust since the RL controllers have no problems with large amounts of input and output signals.
Allow your engineers to focus their energy on designing how the system should behave instead of implementing that performance meticulously using heuristics. Achieve better performance and faster time to market using Modelon Impact and DeepSim. Modelon and minds.ai are working to further improve and extend this technology to other projects in the future.



