強化学習:排熱回収ボイラシステムのためのAIベースコントローラの開発

![]()
本ブログでは、熱回収蒸気発電機システムのAIベースのコントローラを開発するために強化学習(reinforcement learning: RL)を応用した画期的な事例を詳しくご紹介します。Modelon Impactとminds.aiのDeepSimプラットフォームを組み合わせることで、エンジニアは現在のワークフローを変更したり、新しい技術を習得したり、新しいモデルを設計することなく、AIの最新技術を利用することができます。
Modelon ImpactとDeepSimの機能を利用した強化学習
強化学習とは?強化学習(RL)は機械学習の一分野であり、エージェント(知的なニューラルネットワーク、この場合はシステムコントローラ)の目標として、エージェントの現在の環境に影響を与える連続した決定または行動を行うことによって報酬関数の最大化を狙うものです。エージェントの環境(この場合は機械システム)は、シミュレータ、ハードウェアインザループシステム、または過去に記録されたデータセットでモデル化することができます。
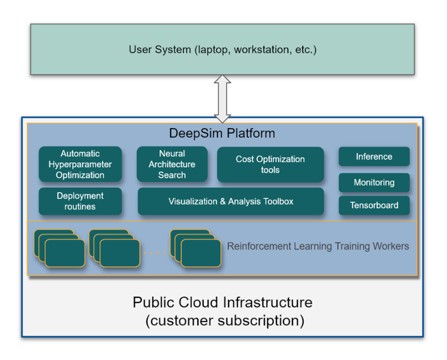
minds.ai のプラットフォーム、DeepSimで知的エージェントをトレーニングする場合、制御されるシステムのロバストで詳細なシミュレーションが非常に重要です。モデロンとminds.aiは、Modelon Impactに付属するソルバーとDeepSimを統合し、この重要な要件に答えるためにパートナーシップを組むことで、当社のすべてのお客様がRLを使用して最も緊急の制御課題を容易に解決することを可能にしています。
Modelon Impactは、独自の使いやすいWebベースのインターフェイスを特徴とする、クラウド利用に対応したシステムシミュレーションソフトウェアプラットフォームで、ユーザーは、サブシステムの階層を移動しながらモデル、コンポーネント、コードの構築や解析などが可能です。モデロンの包括的で実績のある複数の物理ライブラリを内蔵しており、簡単にアクセスすることができます。この開発ワークフローに物理ベースのモデルを使用することの利点は、仮想環境ですべてを開発およびテストできることです。いくつか利点をご紹介します。
- 拡張性 – 計算能力を追加することで、簡単に開発速度を向上させることができます。
- 安全性 – 開発段階で実際のハードウェアは必要ありません。
- 様々なモデル、ハードウェア設計を簡単に検証することができます。
- システムの他の部分との関係性を検証する能力(デジタルツインはシステム全体のボトルネックを容易に検出することができます)。
- 低コスト -ソフトウェア上で完全な設計解析を行うことで、物理的なシステムを構築する必要性がありません。
minds.ai は、コントローラや設計ワークフローを自動化し、お客様の成功を保証するために、グローバルな専用サポートを提供する人工知能製品の会社です。minds.ai のプラットフォーム「DeepSim」は、RLアルゴリズムの複雑な部分を意識せずに使うことができるように設計されており、報酬関数設計を通じて、ドメイン専門家がその専門性をDeepSimに組み込むことができる深層強化学習用プラットフォームです。複数のプロセスでRL学習を並列化することで、DeepSimは割り当てられたリソースを最適に活用しながら、開発と市場投入までの時間を短縮します。
熱回収蒸気発電機
熱回収蒸気発電機(HRSG)は、火力発電所から排出される排ガスの熱を利用して発電を行い、高温のガスを冷却しながら失われる熱エネルギーの大部分を回収する装置です。以下の図2に示すモデルは、Modelon Impactを使用して開発されました。
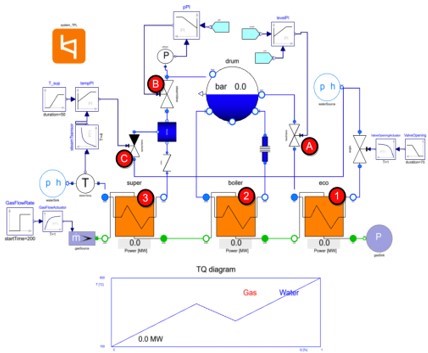
熱回収蒸気発電機には、図2下部のオレンジ色のボックスで表された、異なる相の水を運ぶ3つの熱交換器があります(赤丸の数字は下の数字と対応します)。
- 水はエコノマイザー(右下の熱交換器)を通って入ってきます。他の熱交換器で熱エネルギーの大半を失った排ガスと接触して温度が上昇します。
- 加熱された水はボイラーに入り、その一部は比較的高温の排ガスによって加熱され、ガスに変換されます。このように、ボイラー内では、水は液体と気体の2つの相で存在します。
- 最後に蒸気はスーパーヒーターに入り、そこでさらに排ガスによって加熱されます。排ガスは同じスーパーヒーターを通って熱回収ボイラーに入るため、最高温度となります。
水と蒸気の流入は、PIコントローラで作動する以下の3つのバルブで調整されます。
- 給水弁:エコノマイザで加熱された水がボイラドラムに入り、蒸気と液水が共存する状態を制御します。制御装置は、ドラム内の液水位を一定に保ちます(円A)。
- 蒸気弁:ボイラドラムからスーパーヒーターへの蒸気の流入を制御します。PI制御装置により、ドラム内の蒸気圧を一定に保ちます(丸B)。
- 噴射弁:過熱蒸気を冷却する水噴霧器の開度を調整します。PI制御装置により、排出される蒸気の温度は所定の温度に保たれます(C円)。
強化学習を用いた熱回収発電機向けAIベースコントローラの設計
本プロジェクトは、給水弁、蒸気弁、噴射弁の作動に使用されている3つのPIコントローラを、DeepSimを用いて学習させた強化学習(RL)エージェントに置き換えることを目的としていました。蒸気圧力、蒸気温度、ドラム缶内の水位という3つのセンサーの測定値を、プラント設計者が設定した規定値にできるだけ近づけるために、標準のPIコントローラの性能を凌駕するコントローラを開発することが狙いです。
DeepSimがシミュレータモデルと連動できるようにするためにPIコントローラを外部入力に置き換え、DeepSimが処理すべき操作を指示できるようにしました。これは、Modelon Impactでシームレスにシミュレーション実行するための工程でした。この工程の後、モデルはFMUモデルにエクスポートされ、それがDeepSimプラットフォームに読み込まれました。このワークフローは汎用性があり、Modelon Impactで設計およびサポートされるすべてのモデルに適用できます。
HRSG制御の問題は、RLエージェントがモデルに対して、実行の各タイムステップ毎に送信される3つのコマンドを与えるように設定されました。エージェントはこれらのコマンドに対して異なる値を探索するため、システムが回復不可能な状態になるのを防ぐためにそのコマンド選択範囲は制約されました。経験的に、3つのコマンドは、以下の範囲で性能が良いと判断されました:
- steamValveCommand:033~0.67
- sprayValveCommand:004〜0.083
- feedValveCommand:033〜0.67
同時に、エージェントは次のセンサーの測定値を観測します:蒸気圧力、蒸気温度、およびドラムレベル。
RL問題で最も重要なのは報酬関数の定義であり、この関数はエージェントが最終的に何を最適化するために学習するのかを決定します。
RL制御は、従来のモデル予測制御(MPC)と比較することができます。モデル予測制御では、制御動作は各サンプリング時における有限の制御対象時間区間での開ループ最適制御問題を解くことによって得られます。RLの報酬関数はMPCで用いられる目的関数と類似しており、MPC制御器と同様に、RL制御器は次の制御時刻での環境状態という形でしかフィードバックを受けない開ループ制御器です。しかし、この2つの方法は同じではありません。MPCは制御変数のオンライン計算を必要とするが、RLはトレーニング段階でのみ必要で、展開時には単純な行列の掛け算で十分です。もう一つの違いは、RLソリューションがシステムモデルを用いてパラメータ空間を探索し、報酬を最大化するのに対し、MPC法はシステムモデルと制約条件を用いて目的関数を最適化することです。つまり、モデルの複雑さが増大しても、RLではタスクが難しくなることはありませんが、MPCではそうなります。
AIベースのコントローラの動作から得られる熱回収蒸気発電機システムの結果
この例では,Modelon Impact のような高度なシミュレー ションプラットフォームでうまく機能する近接型ポリシー 最適化アルゴリズムを使用しました。強化学習のアルゴリズムのハイパーパラメータを調整するために32 CPU コアを使用した複数の DeepSim 実験を並行して行い、それぞれの実行において、わずかに異なるパラメータを使用しました。
図3は、最小報酬値と平均報酬値がプラトー(高いほど良い)に達していることを示しており、これはエージェントが見たすべての学習例(シナリオ)で満足していることを表しています。x軸は、エージェントが350万回以上の試行を繰り返してトレーニングされたことを示しています。これは、モデルの更新状態に関する情報を得るために、350万回のシミュレータとの通信があったことになります。
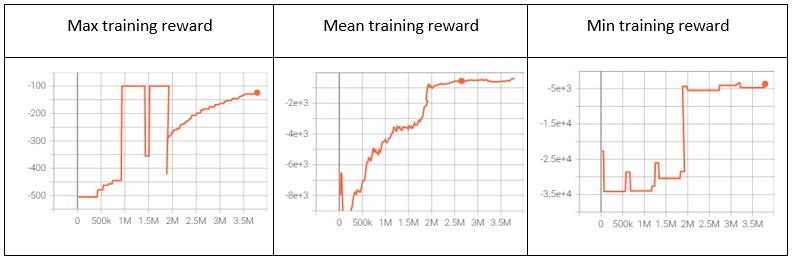
X軸は訓練ステップ数を、Y軸は無次元報酬値を示しています。
RLエージェントコントローラと従来のPIコントローラの性能を検証・比較するために、一連の評価シナリオを使用し、これらのコントローラの動作に対してHRSGシステムがどのように反応するかを評価しました。図4は、評価シナリオの1つを用いて、2種類のコントローラを比較したものです。参考までに、エージェントは対応するPIコントローラと比較されています。これらのプロットでは、1行目は観測値とその設定値を示しています。2行目は、実行されたアクションを示します。最後に、3行目はエージェントの報酬成分と評価エピソードのガス流量を示しており、コントローラの適応性をテストするためにガス流量をランダムに変化させています。図4はまた、RLエージェントが従来のPIコントローラよりも設定値に近づき、さらに重要なことに、より速く反応することを示しています。これは、RLコントローラーが状況の変化に素早く適応していることを示しており、このような高度に動的なシステムにとって重要なことです。
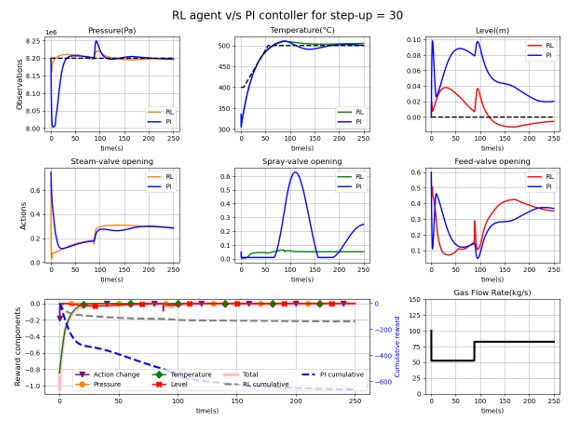
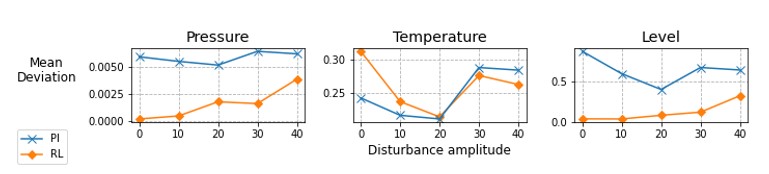
最終的に、RLエージェントとPIコントローラの設定値からの平均偏差を評価すると、図5に示すように、RLエージェントの方が全体的に優れた性能を示しています。入力の外乱の振幅が大きくなるとRLの偏差も大きくなりますが、RLの偏差は基本的にはPIコントローラの偏差を下回っていることがわかります。
結論
Modelon ImpactとDeepSimの2つのプラットフォームを組み合わせることで、ユーザーは現在のワークフローを変えたり、新しい技術を学んだり、新しいモデルを設計したりせずに、AIの最新の開発成果を利用することができます。強化学習を使用してコントローラを生成することで、様々な革新的な設計を迅速に繰り返し、RLコントローラは大量の入出力信号に対して問題がないため、コントローラをより頑強なものにすることができます。
エンジニアは、ヒューリスティックを使って細かく性能を実装するのではなく、システムがどのように動作すべきかを設計することにエネルギーを集中させることができるようになります。Modelon ImpactとDeepSimを使用することで、より優れたパフォーマンスと市場投入までの時間短縮の実現が可能になります。モデロンとminds.aiは、将来的にこの技術をさらに改善し、他のプロジェクトに拡大するために取り組んでいます。


